
Review on Pachyderm by Antoine Scisson

Using Pachyderm for containerised analytics
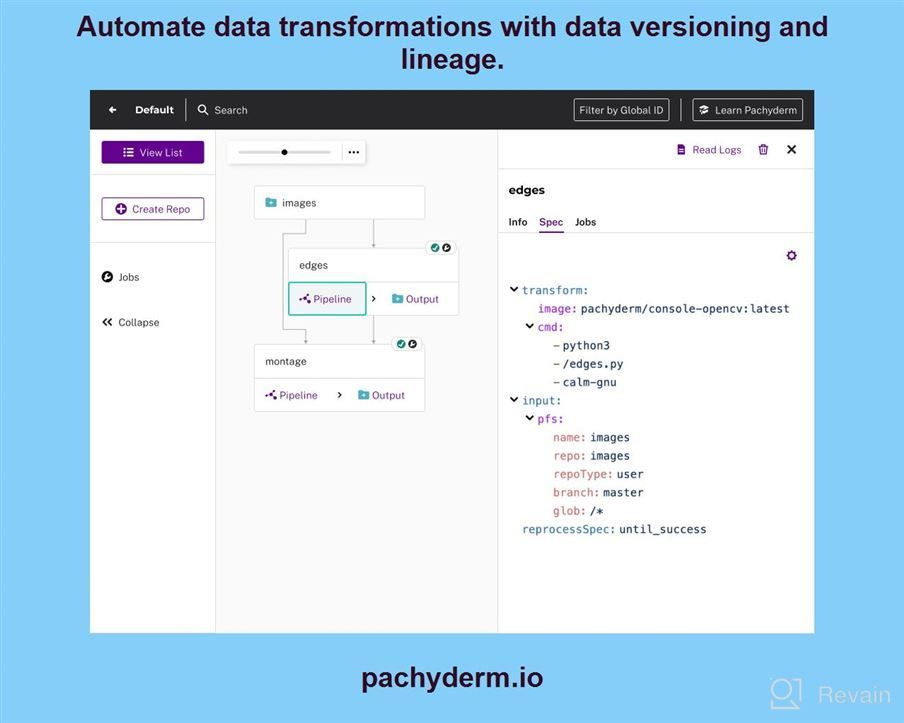
The UI feels very intuitive to use, we can easily configure pipelines with multiple steps using docker compose files. It's easy to integrate it in other applications like Jenkins or any CI/CD system as well. We're able to store our data directly into S3 without managing additional file systems which makes things easier than if you were storing your pipeline jobs on GCP storage buckets (like Google Cloud Storage). Also I really appreciate how they've made all their code available under Apache 2 license so anybody could build something new from scratch by just getting started! There are some limitations when dealing with big datasets but this comes pretty natural considering what pachyslerms offers - having access to a powerful platform with tons of features at no cost. A lot more work was needed before launching production services since there weren't many examples out there about deploying such kind of solutions. Data analysis related.
- Very fast
- Easy integration between different tools.
- Scales horizontally for free,
- Ability not only do run containers locally while developing projects , Integration possibilities through Docker Compose configuration scripts is amazing!, Open source project that has been built mostly during weekends : )
- Not enough documentation around deployment options,
- Lack basic knowledge required building complex deployments









